
At my last startup, we chose Vimeo to get to market quickly. Then came a surprise call from their enterprise team that changed everything, their model would ensure we lost money at scale. So we pivoted, building our own solution on AWS. That “solution” ended up costing us over $100k in credits and peaking as one of our largest expenses. We were drowning in operational overhead, maintaining a fragile stack of CDK, Kinesis, Fargate, SQS and more engineering time that should have been spent on our product.
Somehow, this has become the standard response. Ask a team “how should we handle media?” and the immediate answer is often “we’ll just use S3 and Lambda.” But this instinct, while well-intentioned, leads straight into a maze of configuration, message queues, and boilerplate code. All before you’ve written a single line of business logic. Instead of deliberate design, teams inherit a legacy of unnecessary complexity.
We learned the hard way that building on a complex patchwork of AWS services meant sacrificing agility for operational overhead. Our margins took a direct hit. This frustration is why we built Ittybit on four core principles: it had to be simple to start, easy to extend, built to scale, and still affordable when you got there.
This is the story of our journey from complex, costly infrastructure to a simpler, more powerful solution. We’ll show you the decisions that cost us time and money, and introduce you to a unified API designed to give you back both.
Building a Video Processing Pipeline with AWS
Our first approach followed the AWS process for a seemingly simple task, “extracting frames from a video stream and storing them as images.” What’s represented as “simple” turned out to demand a staggering upfront investment.
The architecture for a single “proof of concept” (their words, not ours) mandates four interconnected services:
- Amazon Kinesis Video Streams
- AWS Fargate task
- Amazon Simple Queue Service (Amazon SQS) queue
- Amazon S3 bucket
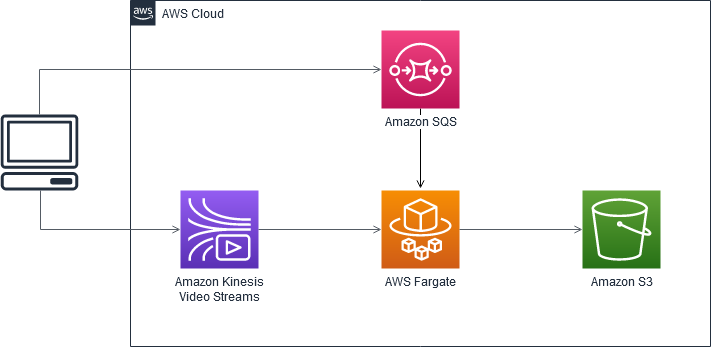
Source: AWS blog
The Proof of Concept Process
- Create a Kinesis Video Stream
- Upload a video
- Craft and send a JSON message to an SQS queue to trigger the process
- A Fargate task polls the queue, runs the application, and finally saves a frame to S3
This four step process is just the recommended starting point. The pattern’s authors include a crucial disclaimer: “This pattern should not be used in its current form in production deployments.”
The next section takes a critical look at the AWS approach. While the prescribed pipeline demonstrates what is possible, it leaves you with a complex system that is hard to operate and scale. Each new requirement like transcoding, transcripts, security scans, or performance tuning adds another service, another Lambda, another queue, and another set of permissions.
We will also share an alternative path which is unified media API that delivers extended capabilities without forcing you into an endless cycle of stitching services together.
Automation and Scaling of AWS Video Pipeline
When we first looked at AWS’s “simple” pipeline, we thought it would get the job done. One file upload, one bucket, everything neat. And to be fair, for the first 100 users, it did. But complexity came in hard. Every new requirement forced us to stitch in another AWS service, another Lambda, another queue, another IAM policy. Suddenly, the “simple” pipeline turned into a distributed system that needed babysitting.
The AWS blog diagram below illustrates the services involved when you migrate your digital assets to the cloud. Even at the starting point, you’re already juggling six separate services.
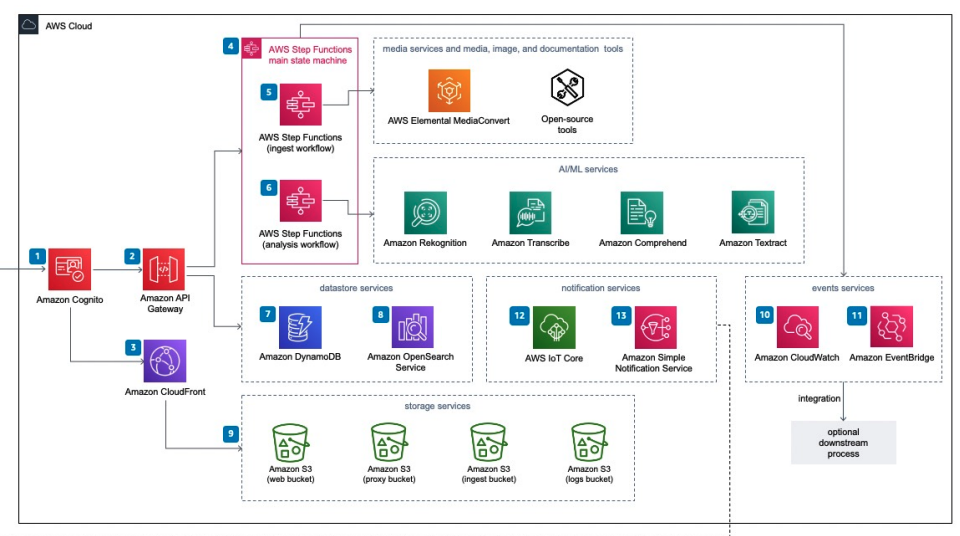
Source: AWS Blog
If the proof of concept pipeline in the previous section with four services felt heavy, AWS’s “product-ready” Media2Cloud reference implementation takes it to a whole new level. Here’s a list of what you should expect when you follow the AWS blueprint.
- Amazon Cognito user pool for authentication
- Amazon API Gateway RESTful API endpoint
- Amazon CloudFront distribution for hosting web artifacts
- AWS Step Functions main state machine for orchestration
- Step Functions ingestion sub-state machine (with MediaConvert for video/audio, plus open-source tools for images/docs).
- And 8 More services
We listed only five services, but when you look at the diagram and the reference docs, the total jumps to thirteen separate services just to ingest and analyze media, and this is what AWS calls the simplified reference implementation.
What This Means in Practice
On paper, this architecture looks impressive. In practice, it means:
- You need engineers who understand authentication, APIs, storage, compute, search, queueing, orchestration, and monitoring.
- Every additional service is another service area for cost debugging, permissions, and operational overhead.
- Even minor changes like adding a new type of analysis or tweaking the workflow will require navigating a maze of Step Functions, IAM roles, and event rules.
You just saw how AWS turns “store and process media” into a dozen services, each with its own dashboard, IAM rules, and CloudFormation templates. That’s great if you want to become an AWS operator. But if your goal is to ship features to your users, you need something simpler.
That’s where ittybit comes in.
Ittybit Media Object vs AWS Media2Cloud
In our test setup, we compared AWS’s reference Media2Cloud deployment with an equivalent workload built on ittybit. Media2Cloud required a CloudFormation template provisioning more than 12 managed services, including Step Functions, DynamoDB, Rekognition, Transcribe, Comprehend, Textract, OpenSearch, S3, SNS, SQS, IAM, Cognito, and CloudWatch.
What if you needed to do more than just extract a frame? What if your requirement was to convert the video to a standard format, compress it for the web, resize it to 1080p, and brand it with a company logo?
AWS Media2Cloud stack (partial):
- 12+ managed services
- 3 state machines for ingestion and analysis
- 4 S3 buckets for intermediate artifacts
- DynamoDB tables for metadata storage
- Integrations across Lambdas, queues, and event rules
By contrast, the ittybit implementation represents the same workload as a single media object, stored and queried through one REST API.
Scenario 1: Video with AI generated Metadata
You are building a video messaging service. Each upload gets converted to a standard format for compatibility, gets checked for NSFW content, and has a description generated for accessibility and search.
Scenario 2: Video Streaming with Subtitles and Thumbnails
Imagine you are now adding a social feed or stories. Each public video needs a poster image, multiple formats for compatibility, and multiple sizes for fast-loading on any device. Users also expect subtitles, chapter markers, and a timeline of thumbnails for easy navigation.
Instead of hooking up another 42 services, the previous automation can just be extended:
Media Infrastructure Evaluation Checklist
When you are choosing how to handle media at scale, the easy default is to reach S3 buckets, Lambdas, and queues. But before you commit to that path, it is worth stepping back. The real question isn’t just can you build it, it is should you. You can use this checklist to test your assumptions and make sure your team’s time and money are going into the right place.
- Access Total Cost of Ownership (TCO): Evaluate beyond the line item cloud bill. Calculate the hidden costs involved like, developer hours spent on boilerplate code, infrastructure configuration, debugging distributed systems, and ongoing maintenance. A solution with slightly higher per GB storage but a simpler API often has a far lower TCO.
- Evaluate Developer Velocity and Focus: Consider the cognitive load and time to launch. How many lines of code, services, and configurations required to ship a basic feature? Prioritize solutions that minimize undifferentiated heavy lifting and allow your team to focus on building your product’s unique value, not the actual media infrastructure.
- Ecosystem and Strategic Fit: Balance the maturity and flexibility of a DIY approach against the focus and velocity of a dedicated API. For core, differentiating technology, building yourself may be justified. For universal needs like media processing, it is best to leverage the best tools that abstract away the complexity.
Working through this checklist often reveals the hidden costs of “rolling your own” media stack. What looks simple at first usually grows into a system that steals developer time and slows down product velocity. This is why in our case, we moved aways from DIY infrastructure and toward a unified media API.
Summing it Up
This experience taught us a universal truth, Building It Yourself (BIY) is complex and expensive. It's a tax on engineering time, a drain on margins, and a distraction from your actual product.
We are flipping that model.
The legacy approach forces you to become an infrastructure company first. You spend months architecting a fragile patchwork of services, writing boilerplate orchestration code, and managing endless configuration, all before you write a single line of unique business logic.
Ittybit is designed to solve this. It is the framework we built from the ground up to avoid that initial $100k pain. We channeled our frustration into a single, unified API that gives developers a clear advantage. With Ittybit, you can:
- Start simply, with a low barrier to entry and quick integration.
- Extend easily, with a flexible architecture that grows with your needs.
- Scale seamlessly, without complex re-engineering.
- Remain affordable, with powerful features that don't come with an exorbitant cost.
We've eliminated the months of integration work, so you can stop building infrastructure and start building features. If your team wants to deploy with confidence and stay focused on your product, don’t default to the complexity of BIY. Start with Ittybit and ship media features in hours, not months.
Get started here https://ittybit.com/ and see how fast media should be.